




Amazonマンガ週末祭り 第2弾、ドラフトキング、クマ撃ちの女など高レビュー作品が50%還元
-
Amazonは、「Amazonマンガ週末祭」を2026年6月の毎週末に実施している。
第2弾として、高評価レビュー作品が50%ポイント還元される。第2弾は6月12日(金)- 6月14日(日)まで。 対象作品は、クマ撃ちの...
2017-08-06
ロジスティック回帰
教科書のデータ
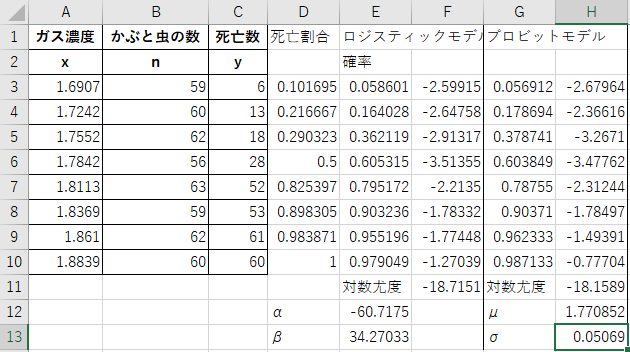
| 表7.2 かぶと虫の死亡データ ガス濃度はlog10CS2mgl-1 | ||||||||||||||||||||||||||||||
出典 |
ロジスティック回帰
表7.2から、ガス濃度毎の死亡割合を計算して図にしました。
このデータに基づいて、死亡確率をガス濃度の関数として表したいと思います。但し確率は0から1の間ですので、直線や多項式を用いると、ガス濃度によっては0から1の範囲をはみ出てしまうので不適です。そこで0から1の範囲をはみ出さないモデルとして次の3つがしばしば使われます。
表の上からi番目の行は、ガス濃度がxiであるときに、かぶと虫ni匹の中のxi匹が死んだということを表しますので、その濃度で各々のかぶと虫が死ぬ確率をpiとすると、死亡数の確率分布は二項分布B(ni,pi)になります。このpiをxiのどのような関数で表すか、という問題を考えます。二項分布の確率関数p(x)=nCxpx(1-p)n-xで、ExcelではnCx=COMBIN(n,x)です。実はこの項にはp(x)が含まれないので省いも構いません。
- モデル1:ロジスティックモデル
- 死亡確率はp(x)=exp(α+βxi)/(1+exp(α+βxi)))である。
- モデル2:プロビットモデル
- 死亡確率はp(x)=Φ((xi-μ)/σ)である。但しΦは標準正規分布の分布関数で、Excelでは Φ((x-μ)/σ))=NORM.DIST(x,μ,σ,1)で書けます。
- モデル3:極値モデル
- 死亡確率はp(x)=1-exp(-exp(α+βxi))である。

次に対数尤度の計算です。二項分布B(n,p)の確率関数はnCxpx(n-p)n-xでした。対数尤度はlognCx+xilog pi+(ni-xi)log (1-pi)をiを1から8まで全部足したものになります。


F12セルの対数尤度を最大にするようなF1、F2セルの値を、ソルバーを用いて求めてください。

モデルによって推定した死亡確率と、実際の死亡割合を比較するとこのようになります。

点は実際の死亡割合、曲線がモデルです。
プロビットモデルに関しても同様にまず確率を求めて、それから対数尤度を計算してみましょう。μは最初はデータの中ごろということで1.8、σはとりあえず1にしてソルバーを使ってください。

すると、分母のσが小さくなりすぎてエラーになりました。

エラーにならないように変数の範囲に制約をつけましょう。

σ=0.02…でエラーになっているので、σ≧0.03にしましょう。制約条件(U)の追加(A)をクリックして、制約式を入力します。

もう一度ソルバーを実行してみます。
今度はエラーになりませんでしたし、σ=0.05…ですので制約の端でもありません。もしもソルバーの解が制約の端である0.03と一致していたら、ソルバーの結果が制約式に依存してしまっているので、制約式を少し広げてσ≧0.025などを試すべきですが、今回は端ではないのでこれで大丈夫です。
最後に極値モデルに関しても最尤推定量を求めてください。α、βの初期値はロジスティックモデル同様α=β=0にします。今度もソルバーでエラーが出ました。

今回は死亡確率が1になっているのは最後の行だけで、ここは60匹全員が死亡しているので尤度としては160で良いのですが、公式にそのまま代入するとnCxpx(1-p)n-xの中の(1-p)n-xの部分が00となり、数学的には1なのですがExcelは底が0だとエラーになってしまいます。エクセルがエラーを起こす(1-p)n-xの部分は、最後の行ではどうせ1を掛けているだけなので削除してしまっても計算式は変わりません。

今回はソルバーで計算することが出来ました。

レポート課題
それぞれのモデルの最尤推定量を求めて、どのモデルが一番良いか選択したエクセルファイルを提出してください。2017-08-03
2017-07-02
ポアソン分布
5月22日の講義に引き続いて、Excelのソルバーを用いて最尤推定量を求めます。5月22日に欠席してソルバーの準備をしていない人は5月22日の講義のページを見て準備してください。
注:5月22日の講義の時と別のパソコンを使っている人は、改めてソルバーの準備が必要かも知れません。 22ページ表2.1のデータです。
22ページ表2.1のデータです。
これらのデータが、どんな母集団分布に従って観測されたのか、特に都市群と農村群で同じ分布と考えるのが妥当なのか、違うと考えるのが妥当なのか、考えます。
母集団分布を寸分の狂いも無く推定するには無限個のデータが必要ですのでそれは諦めて、ポアソン分布を用いて推定してみます。他にももっと適当な分布があるかも知れません。
ポアソン分布の確率関数は f(x|λ)=λxe-λ/x! です。そしてそのグラフをいくつかのλに関して書いてみると

になります。今日はまず都市群のデータ

に一番良く当てはまるλの値を最尤法を用いて求めてみましょう。
また、対数尤度関数をλで微分して=0とおいた式を解いて、λの最尤推定量をx1x2,…,xnを用いた式で書き、その式に都市群のデータを代入した値と比較してください。
注:5月22日の講義の時と別のパソコンを使っている人は、改めてソルバーの準備が必要かも知れません。
教科書のデータ
これまでの講義で何度か使った、都市部と農村部の慢性病の数のデータです。 一般化線形モデル入門
|
|
出典 |
母集団分布を寸分の狂いも無く推定するには無限個のデータが必要ですのでそれは諦めて、ポアソン分布を用いて推定してみます。他にももっと適当な分布があるかも知れません。
ポアソン分布の確率関数は f(x|λ)=λxe-λ/x! です。そしてそのグラフをいくつかのλに関して書いてみると
になります。今日はまず都市群のデータ
に一番良く当てはまるλの値を最尤法を用いて求めてみましょう。
パラメータのベクトルをθとすると、対数尤度関数は∑α=1nlog(f(xα|λ))です。ポアソン分布の場合はパラメータはλ一つですから、θ=λです。ポアソン分布の場合は対数尤度関数をλで微分して=0とおいた式を解くことでλをx1x2,…,xnを用いて表すことも出来ますが、今回は解けない場合に計算機を使ってどうやって求めるか、という問題を考えていますので、Excelで尤度関数の値を求めて、それを最大にするλを探しましょう。
まず都心部のデータをExcelに貼り付けます。説明を合わせるためにA1セルから貼り付けてください。データはA2からA27に入ります。次にλの値を入力します。後で変化させますがまずはλ=1にしましょう。B1セルにλ、C1セルに1と書いてください。
そして対数尤度関数はlog(f(xα|λ))を足したものですので、B2セルに、この式のxのところにA2セルの値が、λのところにC1セルの値が来るように式を書きます。但し、この式を後でB3以降にコピーしますので、C1はC$1と書いて、下へコピーしても番号が変わらないようにしてください。
ポアソン分布の確率関数の式はEXCELでは =POISSON.DIST(x, λ, 0) です。EXCEL2007以前では =POISSON(x, λ, 0) と書きます。また、底がeである自然対数はLN( )です。
練習
D1セルに都市群のデータの対数尤度関数を計算し、C1セルの値を変化させて、対数尤度が最大になるλの値をソルバーを用いて探してください。また、対数尤度関数をλで微分して=0とおいた式を解いて、λの最尤推定量をx1x2,…,xnを用いた式で書き、その式に都市群のデータを代入した値と比較してください。
次に二通りの統計モデルを考えて、最尤推定量を求めます。
都市群と農村群で共通のパラメータを用いるモデルと、別のパラメータを用いるモデルです。
まず農村部のデータを貼り付けます。ひとまとめにして扱うので、都市群のデータの下のA28から貼り付けます。23人分のデータがA29からA51に入ります。
最初は、共通のパラメータを使うモデルを考えましょう。
農村部にもB列にlog(f(xα|λ))の式を書いてください。共通のパラメータを使うのでλはC1セルの値を使います。
対数尤度はそれらの値を全部足したものですので、B52セルに =SUM(B2:B27)+SUM(B29:B51) と書いてください。
目的セル(E)欄に、最大にしたい対数尤度が書かれているB52、変化させるセル(B)欄にパラメータλが書かれているC1と書きます。欄をクリックしてからそれらのセルをクリックしても構いません。
今回は、パラメータλは正でなければなりませんので 制約のない変数を非負数にする(K) にチェックをつけたままにして解決(S)をクリックします。


うまく最適値が見つかりました。OKをクリックすると、対数尤度の最大値がB52に、そして対数尤度が最大になるλの値、つまり最尤推定値がC1に入力されます。
次に都市群と農村群で別のパラメータを用いるモデルを考えます。
E1セルに都市群のパラメータとしてとりあえず先ほど求めた共通のλの値を、E28セルに農村群のパラメータとしてとりあえず同じ値を入力して、D2セルにデータxとしては先ほど同様A2を、パラメータλとしてE1セルを使う式を書いてD27までコピーします。
今度はD29セルに、データxとしてはA29を、パラメータλとしてE28セルを使う式を書いてD51までコピーします。
D52セルにそれらの合計、つまり =SUM(D2:D27)+SUM(D29:D51) を書いて、この値を最大にするようにE1セルとE28セルの数字を変化させます。
SUM(D2:D27)を最大にするE1と、SUM(D29:D51)を最大にするE28を探せばよいのですが、これもソルバーを使いましょう。
最大にする目的セルはD52, 変化させるセルはE1,E28です。

対数尤度の最大値が求まりました。この大きさだけをみて、大きいほうが良い、と考えてはいけません。

AICを求めます。AIC=-2×対数尤度の最大値+2×パラメータ数です。これが小さいほうが良いモデルです。

別のパラメータを使うモデルのほうがAICが小さいので良いモデルといえます。実はこの場合は値の差が1以下なので断言し辛いですが、今回は練習ですので気にしないことにします。

2017-06-20
2017-06-13
Excel VBA入門
Excel VBAの導入を説明しました。
5月30日のExcel入門で使った身長と座高のデータを今回も使います。
出典
5月30日のExcel入門で使った身長と座高のデータを今回も使います。
| 生徒 | 身長 | 座高 |
|---|---|---|
| 1 | 159 | 88 |
| 2 | 150 | 84 |
| 3 | 157 | 86 |
| 4 | 153 | 81 |
| 5 | 158 | 83 |
| 6 | 152 | 85 |
| 7 | 155 | 83 |
| 8 | 157 | 83 |
| 9 | 145 | 76 |
| 10 | 158 | 85 |
| 11 | 161 | 85 |
| 12 | 150 | 83 |
| 13 | 148 | 79 |
| 14 | 154 | 84 |
| 15 | 154 | 85 |
| 16 | 159 | 85 |
| 17 | 149 | 83 |
| 18 | 155 | 86 |
| 19 | 153 | 84 |
| 20 | 160 | 88 |
2017-06-06
2017-05-30
2017-05-22
ソルバーを使って最尤推定量を求める
今日のテーマ
最尤推定量は(対数)尤度を最大にする値としてデータから計算できます。この計算式θ=θ(X1,X2,...,Xn)を具体的に書き表すことが出来る問題もあります(以前のレポートで出しました)が、計算式を求めることが出来ない問題もあります。そこで今日はExcelを使って最尤推定量を求めて、AICを計算し、モデルを選ぶ方法を勉強しましょう。
準備
Excelを立ち上げたら左上の「ファイル」を押して、「オプション」をクリックします。そして左側の「アドイン」をクリックして、下の「管理:Excelアドイン」の横の「設定」をクリックします。


するとアドインの画面に切り替わるので「ソルバーアドイン」にチェックをつけてOKをクリックします。
サンプルデータ
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||
これをコピーしてエクセルに貼り付けてください。散布図を書くとこのようになります。

考えるモデル
パラメータが少ない順番に- 男女共通モデル
- 男女ともY=α+βX+ε, ε~N(0,σ2)
つまり妊娠期間Xに対して体重Yの確率分布は
男女ともN(α+βX,σ2)
推定するパラメータはα, β, σの3つ。 - 傾きだけ共通モデル
- 男児:Y=α1+βX+ε, ε~N(0,σ2)
女児:Y=α2+βX+ε, ε~N(0,σ2)
つまり妊娠期間Xに対して体重Yの確率分布は
男児:N(α1+βX,σ2)
女児:N(α2+βX,σ2)
推定するパラメータはα1, α2, β, σの4つ。 - 男女別モデル
- 男児:Y=α1+β1X+ε, ε~N(0,σ2)
女児:Y=α2+β2X+ε, ε~N(0,σ2)
つまり妊娠期間Xに対して体重Yの確率分布は
男児:N(α1+β1X,σ2)
女児:N(α2+β2X,σ2)
推定するパラメータはα1, α2, β1, β2, σの5つ。
そのためには、まず最初に適当な初期値を与えます。するとExcelのソルバーはそこから出発して真の値に近づいていきます。初期値をどのように与えればよいでしょうか。最初から真の値が分かるならExcelのソルバーに頼る必要はないのですから、真の値に近くてしかも簡単に求められる値を初期値として使います。
直線y=α+βxのαとβの両方を簡単に知ることは出来ませんが、水平な線、つまりβ=0ならば、その高さαは平均値にしておけば大体データに近そうです。この時σは平均値からのずれ、つまり標準偏差にしておきましょう。
そこで早速体重の平均値と標準偏差を求めましょう。Excelに次のように貼り付けます。

A15に平均、A16に標準偏差と書いてから、B15に平均を求める式、B16に標準偏差を求める式を書きます。
B15にはB3からB14までとD3からD14までの平均ということで =AVERAGE(B3:B14,D3:D14) と書きます。先頭の等号を忘れないでください。
B16にはB3からB14までとD3からD14までの標準偏差ということで =STDEV(B3:B14,D3:D14) と書きます。
するとこのようになります。

セルの幅に合わせて四捨五入されますので、人によって表示される値が少し違うこともあります。
この値を参考にしてα, β, σの初期値を決めます。
まずA17, A18, A19セルにα, β, σと書いて
B17セルにはαの初期値として平均値を書きます。適当なところで四捨五入してかまいません。
B18セルにはβの初期値を書きます。傾きが良く分からなくて水平線を引くので0にします。
B19セルにはσの初期値として標準偏差を書きます。これも適当なところで四捨五入してかまいません。

対数尤度の計算
確率関数や密度関数にデータを代入した値が尤度、それにlogをつけたのが対数尤度です。独立な複数の観測値に関して尤度は掛け算になっているので、logをつけて掛け算を足し算にします。log(Πi=1nf(Xi))=Σi=1nlog(f(Xi))
正規分布N(μ,σ2)の密度関数は =NORMDIST(x, μ, σ, 0) です。最後の0を1に変えると分布関数になります。
今回の問題では、xのところが体重yで、平均値μがα+βxです。それにlogを付けますが、Excelでは自然対数は =LN(x) ですのでE3セルに =LN(NORMDIST(B3,B$17+B$18*A3,B$19,0)) と書きます。対応するセルに色がつくので確認してください。

α, β, σに相当するB17, B18, B19の数字の前には$を付けています。これはこの式をコピーして下に貼り付けても番号が変わらないようにするためです。
E4セルからE14セルにも同様に数式を書きます。一つ一つ書いていると手間がかかりますのでE3セルをコピーして貼り付けます。数式の中のセルの番号がどのように変わるか確認してください。
次にF3セルに女児の一人目の対数尤度の式 =LN(NORMDIST(D3,B$17+B$18*C3,B$19,0)) を書きます。

これもF4からF14へコピーして、E3からF14まで全部足したものが対数尤度です。
E15セルに対数尤度と書いて、F15セルに合計を求める式 =SUM(E3:F14) を書きます。

ソルバー
ここが今回のポイントです。これからα, β, σに色々な値を代入して対数尤度が最大になればよいのですが、試行錯誤するのは大変ですのでExcelのソルバーを使います。エクセルの上の列の「データ」をクリックして、右側の「ソルバー」をクリックします。「ソルバー」が見当たらなかったら、このページの上の準備のところを見てください。

するとこのような画面が表示されるので、F15を最大にするためにB17からB19を変化させる、と指定します。
また、αは正の数とは限らないので「制約のない変数を非負数にする(K)」のチェックを外します。さらにソルバーの設定を変えるのでオプションを押します。

「GRG非線形」のタブを選んで、微分係数を「中央」にします。

OKを押してソルバーの画面に戻って「解決(S)」を押すと、対数尤度が大きくなるようにα, β, σの値が調整されて次のメッセージが表示されます。

OKをクリックすると、対数尤度の値が最大になっています。

AICの計算
このようにして求めた対数尤度の最大値からパラメーターの個数を引いた値が一番大きなモデルが、一番良いモデルなのですが、この方法が考えられた経緯から、-2倍して-2×(対数尤度の最大値)+2×(パラメータの個数)
をAIC (Akaike information criterion)といい、マイナスを掛けているのでAICが一番小さなモデルが一番良いモデルです。
このモデルのAICは-2×(-159.265)+2×3=324.53です。
レポート課題
傾きだけ共通モデル、及び男女別モデルについて、最尤推定量及びAICの値を求め、どのモデルが一番良いか選びなさい。2017-04-24
2017-04-11
登録:
投稿 (Atom)

