確率関数、分布関数の値の求め方
二項分布B(n,p)の確率関数P(X=x)はエクセルの関数BINOMDIST(x,n,p,0)で求めることが出来ます。
一方分布関数P(X≦x)はBINOMDIST(x,n,p,1)で求めることが出来ます。
まず正しいコインを10回投げたときに、5回表が出る確率を求めてみましょう。
表が出る回数が5回ですのでxは5, 10回投げるのでn=10, 正しいコインなのでp=0.5, 確率関数なので最後は0です。
前回、合計を求めるときに=SUM(A2:A31)と入力したように、どこかのセルに=BINOMDIST(5, 10, 0.5, 0)と入力します。
次に6回以上表が出る確率を求めてください。今回は講義中に正解を書けないので数字だけ書いておきます。0.376953…となれば正解、入力した式は正しいです。
しかし、BINOMDISTでは10,000回投げたときに5,000回以上表が出る確率を求めようとしてもnが大きすぎて出来ませんので、こんなときは正規分布で近似します。
正規分布N(μ,σ2)の密度関数f(x)はエクセルの関数NORMDIST(x,μ,σ,0)で求めることが出来ます。
一方分布関数P(X≦x)はNORMDIST(x,μ,σ,1)で求めることが出来ます。
練習:Xの確率分布が標準正規分布の時、P(X≦1)を求めなさい。0.841345…となれば正解です。
次に、二項分布B(n,p)でnが大きいときの正規分布による近似が正しいかどうか確かめるために、BINOMDISTでも計算できるn=100で確かめてみましょう。
正しいコインを100回投げたときに表が出た回数をXとします。
P(X≦50)とP(X≦55)をBINOMDISTを用いて求めてみましょう。それぞれ0.539795…と0.864373…となれば正解です。
Xの分布を正規分布で近似するために期待値μと分散σ2の値を求めてください。公式は教科書にまとめてあります。
P(X≦50)とP(X≦55)を正規分布による近似で求めてください。それぞれ0.5と0.841345…となれば正解です。
少し精度が低いですね。講義中に板書した、二項分布の棒グラフと正規分布の密度関数の曲線で囲まれた部分の面積を思い出してください。棒グラフには幅があるので、密度関数を積分するときにもその幅の分だけ広げた方が精度があがります。どのようにすれば精度が上がるか考えてください。0.539828…と0.864334…になります。
一様乱数
1.新しくブックを開いてください。
2.A1セルに[0,1]の一様乱数を作ります。A1セルに =RAND() と入力してください。
3.100個の一様乱数を作るため、A1セルをコピーしてA100セルまで貼り付けます。
4.B2セルに>0.5と入力してください。
5.先ほど発生させた100個の一様乱数の中で、0.5よりも大きいものの個数を調べます。B1セルにCOUNTIF関数を挿入します。「統計」の「COUNTIF」を選択してOKを押してください。
6.範囲にA1:A100、検索条件にB2とそれぞれ入力してください。検索条件は4.で入力した>0.5という条件を指定しています。

7.ファンクションキー「F9」を押すと、新しく乱数を発生させることができます。0.5より大きい個数も、F9を押す度に変化します。
8.これらの値がどの区間に入っているかを調べます。まずC1セルからC11セルに0から1までの数を0.1刻みで、次のように入力してください。

9.度数分布を調べます。ツールタブ→分析ツール→ヒストグラムを選択してください。
10.入力範囲にA1セルからA100セルのデータを選択してください。データ区間に先ほど入力したC1セルからC11セルを選択してください。出力先にはE3セルを指定してください。グラフ作成にチェックを入れてください。最終的には次のような形になっていると思います。

11.OKを押してください。適当にグラフを移動し、広げて見やすい形にしてください。

練習:乱数をA1000まで1,000個発生させて同じことをやってみましょう。どんな違いがありますか。
簡便な正規乱数
1.演習1のワークシートをそのまま利用します。
2.A1セルに12個の一様乱数の和を作ります。A1セルに=RAND()+RAND()+RAND()+RAND()+RAND()+RAND()+RAND()+RAND()+RAND()+RAND()+RAND()+RAND()と入力してください。
このようにするとA1には平均6、分散1の乱数が入力されます。何故でしょう?[0,1]上の一様乱数の平均と分散を計算して、それと定理2.4を使うと求めることが出来ます。
3.先ほどと同じく、A1セルのコピーをA100セルまで貼り付けてください。
4.B2セルには>6と入力してください。するとB1セルに6より大きいものの個数が表示されます。
5.C1セルからC25セルに0から12までの数を0.5刻みで入力してください。
6.演習1と同じ要領でヒストグラムを作ってください。データ区間にはC1セルからC25セルを選択してください。
どんなヒストグラムになりましたか?
練習:乱数をA1000まで1,000個発生させて同じことをやってみましょう。どんな違いがありますか。
二項分布の表
確率関数、分布関数、期待値、分散を公式を使うのではなく定義どおりに求めてみましょう。また先ほどは特定の値にだけ分布関数を求めてみましたが、分布関数全体を求めてみましょう。
まず、分布のパラメータを入力します。

xの欄に0から10まで入力します。一つずつ入れていると大変なので、
まずA6に0を入れた後は自動で埋めましょう。0を入れたセルをクリックして
編集→フィル→連続データの作成を選びます。

列方向に1つずつ10まで増やします。

するとこのようになります。

次に確率関数を入力します。確率関数の式に従ってx=0に対しては
=COMBIN(B$2,A6)*B$3^A6*(1-B$3)^(B$2-A6)
と入力します。

それをB16セルまでコピーして、確率関数の完成です。

次に分布関数を入力します。
x=0に対しては=SUM(B$6:B6)と入力します。

それをC16セルまでコピーします。

次に期待値μ=Σxp(x)を求めます。まずx=0に対して=a6*b6と入力します。

それをD16セルまでコピーします。

それらを合計したものが期待値です。実は期待値はnpとして求めることが出来ます。

次に分散σ^2=Σ(x-μ)^2p(x)を求めます。まずx=0に対して=(a6-d$18)^2*b6と入力します。

それをE16セルまでコピーします。

それらを合計したものが分散です。実は分散はnp(1-p)として求めることが出来ます。

さて、n=10の場合はこのように確率関数、分布関数を計算することが出来ますし、正規近似では近似精度が悪いです。でもnが大きくなると確率関数を計算することが出来なくなる一方、正規近似の精度は良くなります。それで正規分布N(μ,σ^2)の分布関数で近似します。
とりあえずn=10の場合に対してどれくらい近似できるか見てみましょう。
まずx=0に対して
=NORMDIST(a6,d$18,sqrt(e$18),1)と入力します。3番目の引数には分散ではなく
その平方根である標準偏差を代入します。以下の画像では=NORMDIST(a6,d$18,sqrt(e$18),true)と書いています。本当はtrue, falseなのですが、面倒なのでtrueの代わりに1、falseの代わりに0を書いても同じ計算結果が得られるようになっています。

それをF16セルまでコピーします。

さて近似してみましたが、C列とF列を見比べてみると値はかなり異なっています。
今回の講義の最初の方に書いた、棒グラフの幅が原因です。特にn=10だと棒も11個しかないので、その幅の影響が大きいです。
まずx=0に対して
=NORMDIST(a6+0.5,d$18,sqrt(e$18),1)と入力します。つまり幅の分0.5増やしています。

それをG16セルまでコピーします。

如何ですか。小数点以下2桁までは合いました。まだ近似としては不十分ですが、
そもそもn=10ならば直接確率関数を計算した方が話は早いです。
ここまで出来た人は、このSheet1をSheet2へコピーして、n=100の場合について
同じ計算をして見ましょう。これ以上あまりnを大きくすると、確率関数が計算出来なくなったり、出来たとしても確率関数を足すときの誤差が大きくなってしまいます。

発展
もしもExcelを既に勉強していて、今日の内容では物足りない人はもっと本格的なプログラミングに挑戦してください。但しこれ以降は当日説明できないので多めに用意しているテーマです。出来なくても統計学入門そのものの理解には困りません。
まず準備です。左上の丸いボタンを押して、「Excelのオプション」をクリックします。そして「[開発]タブをリボンに表示する」にチェックをつけてOKを押します。
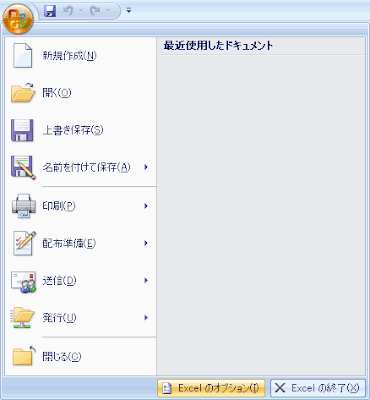
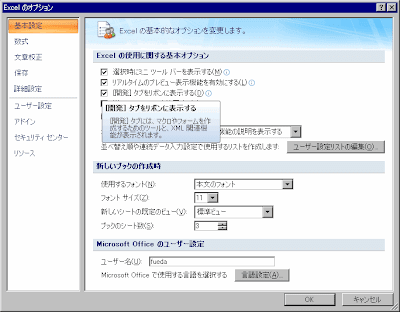
すると右端に「開発」が表示されるのでクリックして、マクロのセキュリティをクリックして、「すべてのマクロを有効にする」に●をつけてOKを押します。
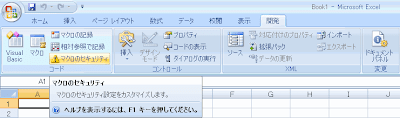
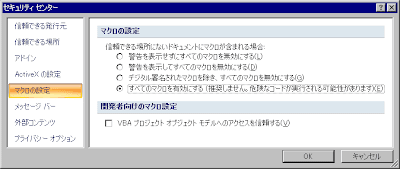
これで準備は完了ですので「Visual Basic」のボタンを押します。するとVisual Basicの画面が開きます。
プログラムを書く部分を用意したいので「挿入」をクリックして「標準モジュール」をクリックしてください。
現れた画面にプログラムを書きます。
まず
sub 練習
とだけ書いて、Enterキーを押してください。すると自動的に
Sub 練習()
End Sub
となり、カーソルは真ん中の空行にあります。そこに
cells(1,1)=1
と書いてください。これは上から1番目、左から1番目のセルに1を代入しなさい、という命令です。
プログラムを書いたら、上の右向きの三角をクリックしてください。するとどのプログラムを実行するか聞かれます。今は一つしか書いていないのでそのまま実行を押すと、A1セルに1が代入されます。Excelの画面で「マクロ」を押しても実行できます。



このプログラムを保存する時の注意。
左上の「上書き保存」を押すと、どの形式でファイルを保存するか尋ねられます。ファイルの種類として「Excelマクロ有効ブック」を指定してください。


さてこれでプログラムを書いて実行できるようになったので、具体的なプログラミングを始めましょう。
先ほどのCells(1,1)=1とEnd Subの間に
cells(2,1)=2
cells(3,1)=3
と書き込んで実行してみてください。
あるいは
cells(1,2)=-2
cells(1,3)=-3
と書いて、cellsの二つの添え字がExcelのどのセルに対応しているか確認しましょう。
10個続けて書くには、
cells(1,1)=1
cells(2,1)=2
cells(3,1)=3
cells(4,1)=4
cells(5,1)=5
cells(6,1)=6
cells(7,1)=7
cells(8,1)=8
cells(9,1)=9
cells(10,1)=10
と書くのは大変なので、これをFor文を使って
for i=1 to 10
cells(i,1)=i
next i
と書きます。
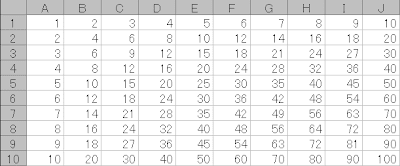
次に下のような九九の表ができるようにプログラムを考えて見ましょう。
シミュレーション
VBAで
Rnd()
と書くと[0,1]区間上の一様乱数が得られます。これを用いて
Sqr(-2 * Log(Rnd())) * Cos(2 * Application.Pi() * Rnd())
と書くと標準正規分布に従う乱数が得られます。(Box-Muller method)
推定方法の良し悪しを比較するために、シミュレーションしてみましょう。
- 標準正規分布に従うデータを、乱数を用いて10個得ます。1行のAからJまで、つまりCels(1,1)からCells(1,10)までに書き込んでください。
データを得たらひとまず「このデータは標準正規分布に従う乱数から得られた」ことを忘れます。
そしてデータだけを見て、この分布の平均、分散を推定してみましょう。元は標準正規分布ですから、平均の推定値はは0、分散の推定値は1に近いほうが良いです。
- まず平均を推定します。10個のデータを足して10で割った値が分布の平均の推定値です。これをL列、つまりCells(1,12)に書き込んでください。
- 次に10個のデータそれぞれから今求めた平均を引いて二乗して足します。足したものをデータの個数である10で割った値をM列、つまりCells(1,13)に書き込んでください。ぴったり平均0、分散1にはならないと思います。
- そこでこのデータ観測と推定を1000回繰り返して、1000個の平均の推定値、分散の推定値を求めて、それら推定値の平均を求めてみましょう。
先ほどは1行目に書きましたが、これを同じことを1000行目まで繰り返します。するとL列、つまりCells(1,12)からCells(1000,12)までに1000個の平均の推定値が、M列、つまりCells(1,13)からCells(1000,13)までに1000個の分散の推定値が得られます。
Cells(1,15)にCells(1,12)からCells(1000,12)までの平均を、
Cells(2,15)にCells(1,13)からCells(1000,13)までの平均を書き込んでください。
Cells(1,15)は0に近いと思いますが、Cells(2,15)は1よりも小さく、0.9前後になるでしょう。
- では今度は1行目から1000行目までの各行に関して、10個のデータから平均を引いて二乗したものを足して(データの個数-1)である9で割ってN列に書き込んでください。
そしてCells(1,14)からCells(100,14)までの平均をCells(3,15)に書き込んでください。
今度は1に近いと思います。
このように、データに基づいて分布の分散を推定するときには(データの個数-1)で割ります。



















